GoogLeNet은 2014년 이미지 분류 대회에서 1위한 알고리즘이다. 구글이 이 알고리즘 개발에 참여했다.
2013년까지와 2014년 부터의 신경망 모델의 차이라고 하면 층 개수가 2배 이상 증가했다는 점인데,
실제로 VGGNet은 버전에 따라 16개의 층 (VGGNet-16), 19개의 층 (VGGNet-19)으로 구현되었고 GoogLeNet은 22개의 층으로 구현되었다.
이렇게 층이 깊어지면
1) 학습할 parameter의 개수가 늘어나고, 연산량 증가
2) 기울기 소실 문제
위의 대표적인 두 가지 문제가 발생한다.
GoogLeNet 개발자들은 신경망 구조에 대한 변화의 필요성을 느끼고 GoogLeNet 만의 여러 특징을 담아 알고리즘을 만들었다.
>> 논문 주소 : https://arxiv.org/pdf/1409.4842.pdf
1. GoogLeNet 구조

구조 상으로 특이한 점들이 몇가지 있다.
1) 1 x 1 Convolution
2) Inception 모듈
3) Average Pooling
4) Auxiliary Classifier (보조 분류기)
이러한 GoogLeNet 만의 효율적인 구조 설계로 성능이 많이 올라갔지만, 복잡한 구조와 적용의 어려움으로 인해 이전 포스팅의 VGGNet (2등)보다 덜 활용되었다.
2. 1 x 1 Convolution

1 x 1 컨볼루션을 하면 피처 맵의 개수를 줄일 수 있다.
피처 맵의 개수가 줄어들면 연산량도 줄어들게 되는데, 아래의 예시를 통해서 확인해보도록 하겠다.
(1) 5 x 5 컨볼루션
입력 : 14 x 14 x 480 피처 맵 (14 x 14 사이즈의 480장 피처 맵)
필터 : 5 x 5 x 480 사이즈의 48장
결과 : 14 x 14 x 48 피처 맵 (14 x 14 사이즈의 48장 피처 맵)
연산량 : (14 x 14 x 48) x (5 x 5 x 480) = 112,896,000
(2) 1 x 1 컨볼루션
입력 : 14 x 14 x 480 피처 맵 (14 x 14 사이즈의 480장 피처 맵)
필터 1 : 1 x 1 x 480 사이즈의 16장
결과 1 : 14 x 14 x 16 피처 맵 (14 x 14 사이즈의 16장 피처 맵)
필터 2 : 5 x 5 x 16 사이즈의 48장
결과 2 : 14 x 14 x 48 피처 맵 (14 x 14 사이즈의 48장 피처 맵)
연산량 : (14 x 14 x 16) x (1 x 1 x 480) + (14 x 14 x 48) x (5 x 5 x 16) = 5,268,480
(1)의 결과와 (2)의 결과가 동일하지만, 연산량에서는 많은 차이가 나는 것을 확인할 수 있다.
1 x 1 컨볼루션은 파라미터 수를 감소시키는 기능을 하는데, 실제로 AlexNet보다 GoogLeNet의 파라미터 개수가 12배나 적다고 한다. (GoogLeNet이 더 깊은 신경망이다!)
3. Inception 모듈
딥러닝에서 신경망 성능을 높이기 위해서 깊이를 깊게 만들거나 채널 수를 늘리는 방법이 있다.
기존의 Dense한 Fully Connected 구조로 구현을 하면 오버피팅 및 연산량 증가의 문제가 발생하게 되고, 이를 해결하기 위해서 GoogLeNet은 Sparse한 구조로 알고리즘을 구성했다.
그러나 문제는 컴퓨터 구조 상 Sparse한 구조는 연산 효율이 떨어진다는 것이다. (대부분의 가중치 값이 0이기 때문에)
따라서 Sparse하지만 Connected된 형태를 만들기 위해서 서로 상관도가 높은 것들을 군집화하여 Dense한 형태로 만들기로 했다.
그렇게 해서 만들어진 구조가 Inception 모듈이다.
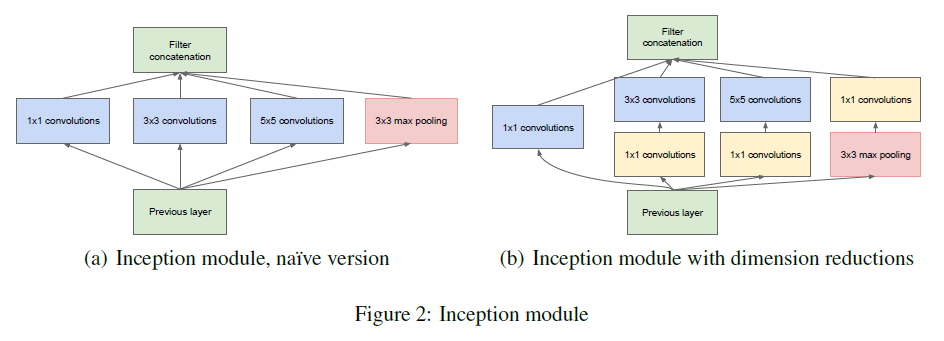
(b)는 2에서의 1 x 1 컨볼루션까지 포함되어 있는 버전이므로, (a)를 살펴본다.
Previous Layer에서의 피처 맵을 1 x 1 컨볼루션, 3 x 3 컨볼루션, 5 x 5 컨볼루션, 3 x 3 Max Pooling 해준 결과를 병렬적으로 Filter Concatenate 해준다.
VGGNet에서는 동일한 크기의 filter (3 x 3)를 사용하였지만, GoogLeNet에서는 다양한 필터 크기를 사용함으로써 더 다양한 종류의 특성이 도출될 수 있다.
4. Average Pooling
AlexNet이나 VGGNet에서는 Fully Connected 방식으로 망의 후반부를 구성하여 1차원 벡터로 만들었다면,
GoogLeNet에서는 평균 풀링 방식으로 1차원 벡터로 만들어 Softmax 함수에 입력한다.
이 평균 풀링의 장점은 가중치가 필요없다는 것인데, 이를 예시를 통해서 살펴보도록 하자.
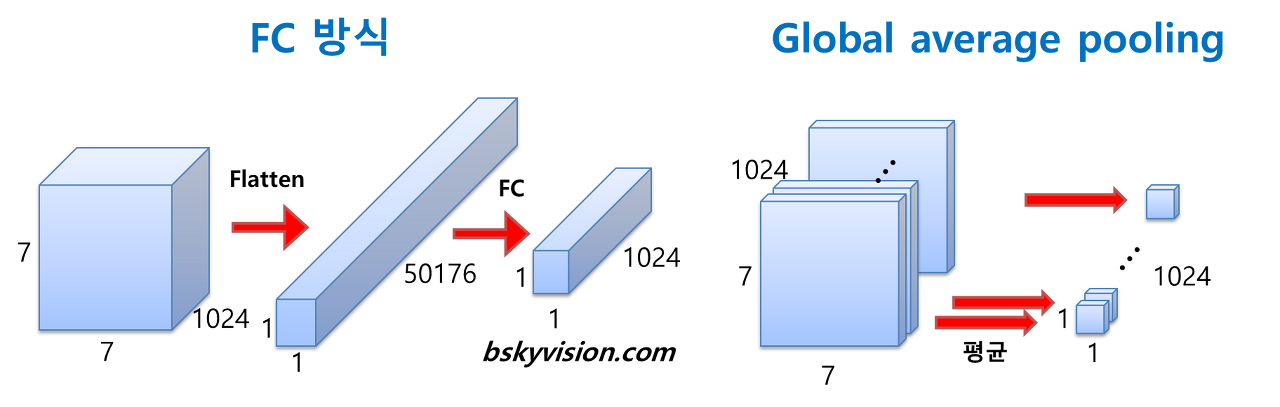
(1) Fully Connected 방식
입력 : 7 x 7 x 1024 피처 맵
Flatten 결과 : 1 x 1 x 50176
FC 결과 : 1 x 1 x 1024
가중치 개수 : 7 x 7 x 1024 x 1024
(2) Average Pooling 방식
입력 : 7 x 7 x 1024 피처 맵
Average Pooling 결과 : 1 x 1 x 1024
가중치 개수 : 0
5. Auxiliary Classifier (보조 분류기)
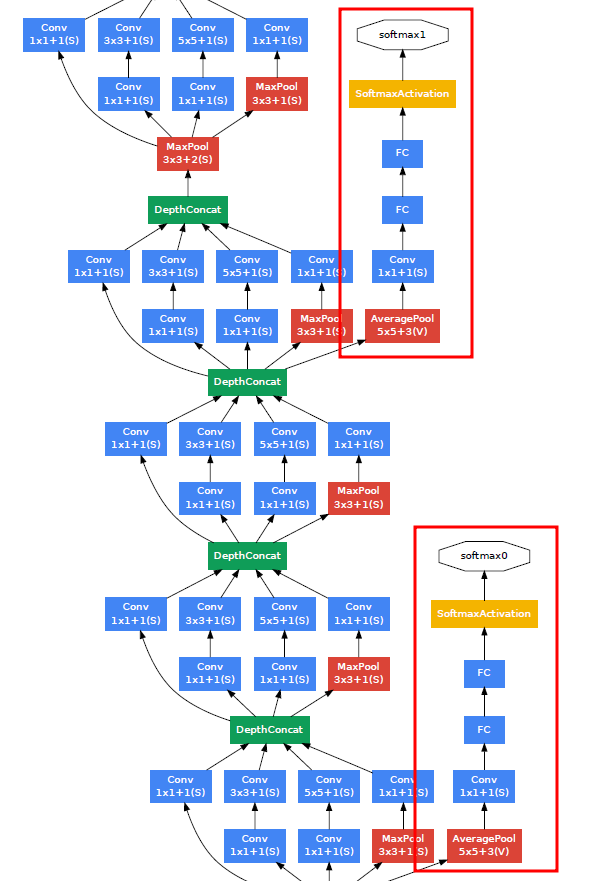
신경망이 깊어질수록 가중치 매개변수의 기울기가 점점 0에 가까워는 현상인 '기울기 소실 (Gradient Vanishing)' 문제가 발생한다. 그러다보면 역전파의 기울기가 사라지고 가중치 update 및 학습이 제대로 이루어지지 않기 때문에 이를 해결하고자 보조 분류기를 붙였다.
보조 분류기를 붙여서 중간 결과에 대한 추가적인 역전파를 발생시킨다. 그래서 기울기가 소실되지 않고 전달될 수 있도록 정규화 효과를 일으킨 것이다.
이는 학습 시에만 사용했으며, 평가 시에는 보조 분류기를 사용하지 않는다.
참고 자료 : https://velog.io/@woojinn8/CNN-Networks-3.-GoogLeNet / https://bskyvision.com/entry/CNN-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%EB%93%A4-GoogLeNetinception-v1%EC%9D%98-%EA%B5%AC%EC%A1%B0
'[ 딥러닝 ]' 카테고리의 다른 글
| Sigmoid가 Activate Function으로 안 쓰이는 이유 / Saturation / 지그재그 가중치 업데이트 (0) | 2023.07.29 |
|---|---|
| [ CNN ] ResNet / 층이 깊어지면 성능도 좋아지게! (0) | 2023.06.07 |
| [ CNN ] VGGNet / 단순하지만 용이하게! (0) | 2023.06.05 |
| 딥러닝의 심층 표현이 중요한 이유 (0) | 2023.06.05 |
| 가중치 감소 (Weight Decay) (0) | 2023.06.02 |



