오버피팅은 가중치 매개변수 값이 커서 발생하는 경우가 많다.
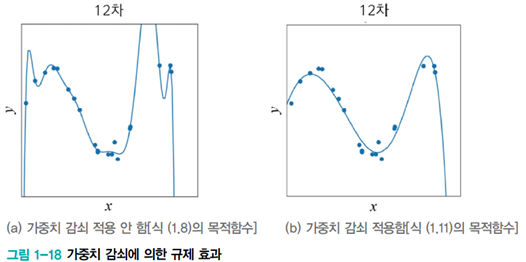
학습 데이터를 늘리는 것이 가장 좋은 방법이겠지만, 추가로 학습 데이터를 확보하는 것은 매우 어려운 일이다.
따라서 가중치 감소를 통해서 오버피팅을 방지하도록 한다.
1. L2 Norm
가장 많이 사용되는 L2 Norm은 '제곱 Norm 정규화'라고도 불린다.
L2 Norm에 대한 가중치 감소를 진행하는 것인데, 값을 줄여야 하는 식은 다음과 같다.

원래의 손실함수 + 가중치 벡터의 크기에 대한 패널티를 주는 요소들
λ 는 정규화의 세기를 조절하는 하이퍼파라미터이다. 이 값이 클 경우에 큰 가중치에 대한 페널티가 커진다.
그럴 수밖에 없는게 λ가 크면 그만큼 더 가중치를 줄여야지만 전체 손실함수 값을 줄일 수 있기 때문이다.
왜 제곱을 할까? 그 이유로는 총 두 가지가 있는데,
(1) 미분 계산이 쉬워지도록 하는 연산의 편의성 때문에
(2) 작은 가중치 벡터들보다 큰 가중치 벡터에 더 많은 패널티를 부여하기 위한 통계적인 성능 향상 때문에
(이차함수는 x값이 작을 때보다 클 때 함수값이 더 크다는 사실!)
2. L1 Norm
L1 Norm은 가중치의 절대값을 가지고 손실함수를 구성한다.

L1 Norm은 L1 Regularization과 Computer Vision에서 사용된다.
3. L∞ Norm
상한 노름 (Maximu

m Norm)이라고도 하는데, 벡터 성분의 최댓값을 구한다.
'[ 딥러닝 ]' 카테고리의 다른 글
| [ CNN ] VGGNet / 단순하지만 용이하게! (0) | 2023.06.05 |
|---|---|
| 딥러닝의 심층 표현이 중요한 이유 (0) | 2023.06.05 |
| 배치 정규화 (Batch Normalization) (0) | 2023.05.31 |
| 가중치 초기화 (Weight Initialization) (0) | 2023.05.31 |
| Optimizer / SGD, Momentum, Adagrad, Adam, RMSProp (0) | 2023.05.30 |



