Optimizer는 알아서 책임지고 매개변수를 최적화해준다.
매개변수를 최적화하는 방식에는 여러 개가 있다.
전반적인 비교를 먼저 보면

1. SGD (Stochastic Gradient Descent, 확률적 경사하강법)
경사하강법은 전체 데이터를 모두 사용해서 기울기를 계산하기 때문에 학습하는데 많은 시간이 필요하다.
이런 점을 보완하기 위해서 확률적 경사하강법이 사용된다.
매 과정에서 한개의 sample을 무작위로 선택하고 그 하나의 sample에 대한 기울기 계산을 수행한다.
배치 크기가 1인 경사하강법이라고 생각하면 된다.
SGD optimizer는 구현하기가 쉽고 단순하다는 장점이 있다.
한편, 비효율적일수도 있다는 점인데 특히 비등방성 함수에서의 탐색 경로가 비효율적이다.
등방성 함수는


z = x^2 + y^2 과 같이 모든 위치에서의 성질이 동일한 함수로,
오른쪽 그림을 보면 해당 함수의 최솟값인 (0,0)을 모든 점에서 가리키고 있는 것을 확인할 수 있다.
비등방성 함수는
z = 1/20 * x^2 + y^2 과 같이 특정한 방향으로 보면 평소와 다른 성질이 보이는 경우가 존재하는 함수이다.

위의 그림을 보면 해당 함수의 최솟값이 (0, 0)을 가리키고 있지 않은 것을 확인할 수 있다.
이러한 비등방성 함수에서는 탐색 경로가 비표율적이다.

탐색 경로가 지그재그로 나타나는데 그 이유는!
기울어진 방향이 본래의 최솟값과 다른 방향을 가리켜서이다. 단순히 기울어진 방향 쪽으로 이동해봤더니 최솟값에 도달하지 못한 것이다.
2. Momentum
모멘텀은 관성인데, 외부에서 힘을 받지 않는 한 정지해 있거나 운동 상태를 지속한다는 개념이다.

가속도 x 원래 속도 - 학습률 x 손실함수 기울기
같은 방향의 학습이 진행되면 가속을 가지고 더 빠른 학습을 기대한다.
가속도로 표현되는 알파 값은 마찰이나 공기 저항과 같은 것으로 주로 0.9로 설정해둔다.
진행하던 속도에 관성이 적용되는 것이므로 안장점을 만나거나 local minimum에 빠지더라도 벗어날 수 있다.
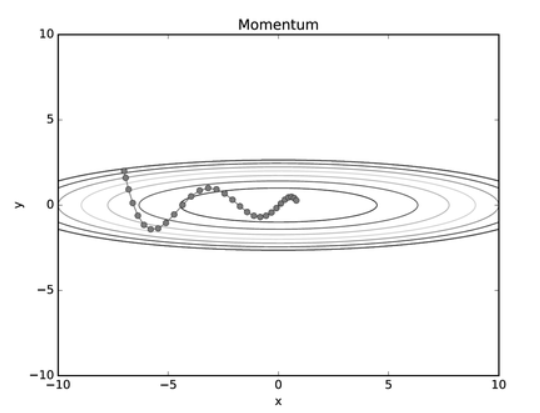
위의 SGD와는 달리 공이 바닥을 구르는 듯한 모습으로 탐색 경로가 그려진다.
x축의 힘이 작고 방향이 변하지 않는데, y축의 힘이 크고 상하로 방향이 변하면서 최적의 값을 찾고 있다.
SGD보다 x축으로 빠르게 다가가서 덜 지그재그의 모습인 것이다.
3. Adagrad (Adaptive Gradient)
학습률이 너무 크면 최솟값을 찾지 못하고 발산해버리며,
학습률이 너무 작으면 시간이 오래걸린다.
따라서 학습률을 특정 값으로 설정해두기엔 너무 비효율적이다.
Adagrad는 학습률을 고정하지 않고, 처음에는 크게 학습을 하고 나중에는 조금씩 학습한다. (학습률 감소, learning rate decay)
각각의 매개변수에 맞춤형으로 값을 만들어준다.

과거의 기울기의 제곱 값을 계속 더해나간다. 해당 값 (h)를 역수로 취해주다보니 학습이 진행될수록 갱신 강도는 낮아진다.
그러면 학습을 무한대로 계속 진행하면 어느순간부터는 갱신하는 양이 매우 작아질 것이다.
이러한 점을 개선한 것이 RMSProp이다. 아래에서 살펴보기로 한다.
4. RMSProp (Root Mean Square Propagation)
AdaGrad와 유사하게 매개변수 별로 학습률을 조절하고 싶은 경우에,
과거의 모든 기울기를 균일하게 더하지 않고, 최근의 과거 기울기에 더 큰 가중치를 주는 방식이다.
같은 비율로 기울기를 누적하는 것이 아니라 지수이동평균 (EMA)을 활용하여 기울기를 업데이트한다.
AdaGrad보다 더 오랫동안 학습할 수 있다는 것이 장점이다.
5. Adam (Adaptive Moment Estimation)
Momentum과 RMSProp의 장점을 결합한 알고리즘으로,
매개변수를 공간 효율적으로 탐색하는 Momentum의 장점과
매개변수 별 적응적으로 갱신 정도를 조정하는 RMSProp의 장점을 합친 최적화 방식이다.
바닥이 구르듯 움직이며, 공의 좌우 흔들림이 덜해진다.
6. 어떤 optimizer를 사용해야 할까?
풀어야 하는 문제에 따라 다르다.
어떤 하이퍼파라미터를 설정했는지 등에 따라서 다르기 때문에
뭐가 특별하게 대단히 뛰어나고 그런 것은 없다.
실제로 아직도 SGD를 쓰는 곳도 많다! 그 중에서도 Adam을 딥러닝에서 가장 많은 사람들이 만족하며 사용하고 있다.
'[ 딥러닝 ]' 카테고리의 다른 글
| 딥러닝의 심층 표현이 중요한 이유 (0) | 2023.06.05 |
|---|---|
| 가중치 감소 (Weight Decay) (0) | 2023.06.02 |
| 배치 정규화 (Batch Normalization) (0) | 2023.05.31 |
| 가중치 초기화 (Weight Initialization) (0) | 2023.05.31 |
| Metric vs. Loss Function (0) | 2023.05.30 |



