
1. Structure of Relational Databases
(1) Relational Model
- 오늘날 상업적으로 가장 많이 쓰이는 모델
- 매우 simple 하며 활발한 update가 이뤄지고 있다.
- low level 데이터 구조들에 대해 independence 속성을 가지고 있다.
- 이 때문에 데이터 저장의 새로운 접근이 발달할 수 있었으며, modern column-stores이 가능해졌다.
- column-stores는 큰 규모의 data mining (데이터 채굴)이 가능해졌다.
※ columnstore : 열과 행이 있는 테이블로 논리적으로 구성되는 데이터로, 열 데이터 서식으로 물리적으로 저장된다.
(2) Relations
- RDB (Relational Database)는 table (== relation)의 모음을 포함하고 있다.
ex. University information system (UIS) - an instructor table, a student table, a course table
- Tuple : data를 구분할 수 있는 단위로, row 값에 해당한다.
- Attribute : relation의 속성 값으로, column에 해당한다.
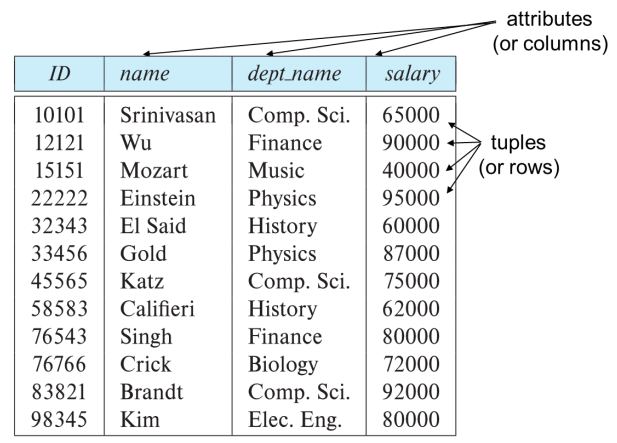
(3) Attributes
- Attributes : A1 , A2 , …, An
- Domains : D1 , D2 , …, Dn
- Domain은 각각의 attribute에 대한 value들의 집합이다.
- Domain은 atomic한 특징을 가지고 있다. 무조건 하나의 요소 당 하나의 값만 들어가야 한다. 즉, list, array 등은 domain 값이 될 수 없다.
- Domain의 null 값은 unknown 또는 존재하지 않는 값이다. 가능한 제거하는 것이 좋다.
- Relation r은 Domain 집합인 D1 x D2 x … x Dn의 부분집합이다.
- 따라서, relation은 n-tuples (a1 , a2 , …, an - attribute 각각의 원소)의 집합이다.

(4) Relations are Unordered
- tuple들의 순서는 무의미하다.

- 같은 relation이며 차이가 없다. ID 값을 순서대로 정렬한 것과 그렇지 않은 것 뿐이다.
(5) Database
- DB는 다수의 relation 조합으로 구성된다.
ex. 대학교는 여러 부분으로 구성된다. : instructor, student, advisor 등
- Bad design 요소 : 너무 많은 attribute 개수

- 결과
ⓐ information의 중복 (두 명의 학생이 동일한 교수님 아래에 소속됨)
ⓑ null value의 등장 (지도 교수가 없는 학생이 있을 수도 있음)
(6) 퀴즈

Q1. How many attributes are in a “STUDENT” relation?
A1 : 7
Q2. How many tuples are in a “STUDENT” relation?
A2 : 5
Q3. Which cases should we consider null values?
A3 : Home_phone, Office_phone
Q4. What is the domains of each attribute in a “STUDENT” relation?
A4 :

2. Database Schema
(1) Database Schema and instance
- Database Schema : database의 논리적 구조. 변수 설정에서 변수 이름 같은 역할.
- Database instance : database의 data 값. 변수 설정에서 변수 값 같은 역할.
- relation schema : attributes 집합
- A1 , A2 , …, An attribute에 대한 relation schema를 다음과 같이 표기한다.

ex. instructor (ID, name, dept_name, salary)
- relation instance : domain 집합
- 변수 값의 차이점으로는 값이 바뀌지 않는 다는 점이다.
(2) Example of the Instructor Relation

(3) Schema design
- 목적 : DB를 design하고 서로 다른 relation 간의 tuple을 연결할 수 있도록 한다.
- 정보의 중복을 최소화하고 정보를 통합하여 원하는 정보를 얻을 수 있게 한다.
ex. 가을 학기에 열리는 모든 강의들에 대한 정보를 찾고싶다면?

공통된 attribute 값인 ID로 두 relation을 합친다.
3. Keys
- tuple 간의 구분이 이뤄지려면 유일한 값이 필요하다.
ex. 동일한 이름 (James), 동일한 나이 (Age), 동일한 학과 (Dept.)를 가진 두 tuple을 구분해야 한다.

Num은 key 값이 될 수 없다. 그 이유는 변할 수도 있는 값이기 때문이다.
- Key 값의 조건
① unique
② not null
③ no change
(1) super keys
- 식별 가능한 모든 attribute (key 값이 될 수 있는 모든 후보군)
- K : relation R의 super keys 집합
ex. {ID} 와 {ID,name} 모두 superkeys 이다.
(2) Candidate key
- super key 중에서 attribute의 개수가 가장 작은 값
ex. {ID} (1개이므로!)
(3) Primary key
- candidate key 중 하나로, 사용되는 key이다.
- 대표성이 있으며 값이 바뀌지 않아야 하고, tuple을 유일하게 식별할 수 있어야 한다.
- primary key constraint : 무조건 relation schema에 존재해야 한다.

(4) Foreign key
- 한 relation 안의 key가 다른 relation 안의 다른 attribute로 사용된다.
- Referencing relation : foreign key를 key 값이 아닌 다른 attribute로 사용하는 relation
- Referenced relation : foreign key를 key 값으로 사용하는 relation
ex. Instructor relation은 Referencing relation이고, Department relation은 Referenced relation이다.

ex. University information system

'[ CS 전공 ]' 카테고리의 다른 글
| [ OS ] Basic component, ISA, Instruction Cycle, PIC (0) | 2022.03.27 |
|---|---|
| [ DB ] Relational Model (2) : Relational Algebra (0) | 2022.03.26 |
| [ DB ] 데이터베이스 Introduction (2) : DB Language, Design, Engine, Architecture, Users and Administrators (0) | 2022.03.17 |
| [ DB ] 데이터베이스 Introduction (1) : DB 정의, DBMS, DB System (0) | 2022.03.10 |
| [ 네트워크 ] ARP 통신 (0) | 2022.03.03 |



