
1. Database Languages
(1) 종류
- DDL (Data Defined Language) : Data의 정의는 곧 Data의 구조 (Schema)이다. 데이터 정의 언어라고 불린다.
- DML (Data Manipulation Language) : Data를 DB 쿼리문으로 나타낸다. 데이터 조작 언어라고 불린다.
- 실질적으로 구분해서 사용하지는 않지만, 하나의 DB 언어의 부분을 형성한다.
- 그 언어가 바로 SQL (Structured Query Language)이다.

(2) DDL (Data Defined Language)
- Database schema를 정의하기 위한 세부적인 표기법이다.
- Data를 생성하고, 삭제하고, 수정하는 등의 전체적인 데이터 골격을 결정하는 언어이다.

- DDL compiler는 data dictionary 안에 저장되어 있는 table template들의 집합을 생성한다.
- Data dictionary에는 metadata가 포함되어 있다.
(※ metadata : 데이터를 설명하기 위한 데이터. ex. 소리바다에서 다운받은 MP3에서 artist, 길이, 앨범명 등이 metadata라고 할 수 있다.)
: Database schema, Integrity constraints (Primary Key - 유일하게 식별 가능한 attribute), Authorization (접근 권한)
(3) DML (Data Manipulation Language)
- 적절한 data model을 만들기 위해서 data에 접근학 수정할 수 있도록 하는 언어
- DML은 query language로 알려져 있다.
ⓐ Procedural DML
: 사용자가 어떠한 데이터가 필요한지, 어떻게 데이터를 가져올 것인지를 설명한다.
ⓑ Declarative DML (Non-procedural DML)
: 사용자가 어떠한 데이터가 필요한지 설명하고, 원하는 데이터를 바로 얻을 수 있는 방식이다.
- Declarative DML이 Procedural DML보다 배우고 사용하는 데에 더 쉽다.
(4) SOL Query Language
- SQL은 nonprocedural DML이다.
- 여러개의 table을 입력받고, 하나의 테이블을 return한다.
- Select + From + Where
ⓐ Select : 실질적으로 찾는 내용 (attribute)
ⓑ From : relation
ⓒ Where : 조건
ex. Find all instructors in Comp. Sci. dept

instructor relation 내의 dept_name이 'comp.sci'인 사람의 name은?
ex. Find the ID and building of instructors in the Physics dept

instructor와 department relation 내의 instructor의 dept_name이 'department.dept_name'이고,
department의 dept_name이 'Physics'인 사람의 ID 값과 부서의 building 이름은?
(5) DB Access from Application Program
- SQL은 Turing machine equivalent language가 아니다. 즉, 조건문, 반복문, 메모리의 주소 등을 바꿀 수 없다는 의미이다.
- 더 다양한 기능이 필요하다면, 다른 higher-level language와 embedded 되어야 한다.
- Application program들은 일반적으로 database에 접근할 때
ⓐ SQL을 embedded할 수 있는 언어
ex. c, c++
ⓑ SQL query들이 보내질 수 있는 인터페이스
ex.ODBC (Open DB connectivity), JDBC (JAva DB connectivity)
2. Database Design
(1) Logical Design
- Database schema을 결정한다. Relation schema들의 집합 중에서 'good'을 찾기 위한 것이다.
ⓐ 실무적 결정 : 적합한 attribute 찾기 (attribute 개수, 중복 최소화)
ⓑ 학업적 결정 : ralation들 간의 관계에서 attribute 결정하기
(2) Pysical Design
- Database의 physical적인 layout을 결정한다. file organization, 내부적인 저장 구조 등을 design한다.
ex. 다음 relation의 문제점 ?

: Data Redundancy (쓸데없는 반복)
building과 budget은 필요 없는 attribute이다.
위의 Database design을 다음과 같이 고쳐본다.

3. Database Engine
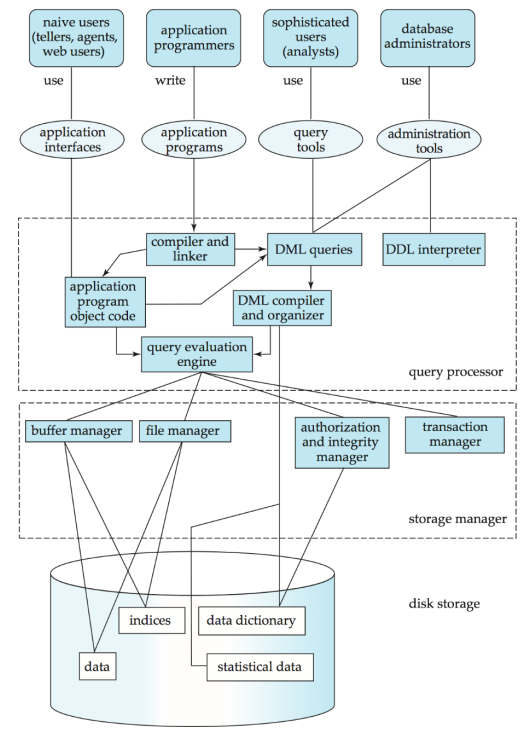
- Database system은 기능 별로 모듈화되어 있다.
① The Storage manager (저장 관리자)
② The query processor component (쿼리 처리자)
③ The transaction management component (일관성 유지 관리자)
(1) Storage manager
- program 모듈은 data (low-level)와 application program, query들 사이의 interface를 제공한다.
- 따라서 storage manager은 OS file manager와 상호작용하면서, 더 효과적으로 저장하고 수정하고 update할 수 있도록 한다.
- Authorization and integrity manager (권한, 제약 조건)
- Transaction manager (consistency 유지)
- File manager (file data 관리)
- Buffer manager (buffer 관리)
- storage manager은 여러 데이터 구조들을 관리하기 위해 다음과 같은 요소를 확인한다.
ⓐ Data files (database 자체)
ⓑ Data dictionary (DB 구조에 대한 metadata)
ⓒ Indices (목차 - 데이터에 더 빠르게 접근할 수 있음)
(2) Query processor
- DDL interpreter, DML interpreter, Query evaluation engine으로 구성된다.
- DML interpreter는 SQL을 기계어 (relational algebra)로 바꾸는 역할을 한다.
- Query Optimization : DML interpreter는 동일한 결과를 내는 서로 다른 쿼리문 중에서 가장 낮은 비용의 쿼리를 찾을 수 있어야 한다.
- Query evaluation engine은 명령어를 실행하는 역할을 한다.
- Query Processing
① Parsing and translation
② Optimization
③ Evaluation

(3) Transaction Management
- transaction : atomicity와 비슷한 뜻을 가지고 있다. 하나의 논리적인 기능으로서 operation들의 묶음이다.
ex. 예금과 출금
- transaction management는 database를 consistent (일관적)한 상태로 보장해야 한다.
- concurrency-control manager은 동시 접근을 보장해야 한다.
4. Database and Application Architecture
- Database system은 기본적인 computer system에 영향을 많이 받는다.
(1) Computer system에 따른 Database system 종류
ⓐ Centralized databases
: 공유된 메모리를 가지고 적은 수의 CPU core를 가지고 있는 컴퓨터 환경
ⓑ Client-Server
: 일반적인 웹 서버의 환경. 하나의 서버에 데이터베이스가 존재하고, 여러 client 서버에서 이 데이터베이스에 접근하는 형태
ⓒ Parallel databases
: 다수의 CPU가 하나의 공유 메모리에 접근하는 형태. 다수의 CPU가 병렬적으로 data를 처리하며, core가 Centralized database보다 많기 때문에 더 빠른 속도를 가짐. 대신에, memory가 공유되므로 어떤 data가 memory를 선점하는지가 중요한 포인트가 됨
ⓓ Distributed databases
: 분산 데이터베이스로, 컴퓨터들이 물리적으로 떨어져 있을 때 사용하는 데이터베이스. 다수의 기기들을 하나의 네트워크로 연결해서 서로 통신하며 동시에 작업. 데이터를 여러 곳에 저장해서 데이터가 안전하게 처리됨.
※ 병렬 처리 방식 : 여러 개의 프로세서들이 각자의 업무를 맡아서 동시에 여러 프로세서를 작동시키는 방식 (동시에 여러 일)
※ 분산 처리 방식 : 처리할 수 있는 장비를 네트워크로 상호 연결하여 전체적인 일의 부분 부분을 나누어 더 빨리 처리하는 방식(하나의 일을 여럿이서 같이 빠르게)
Database Architecture (Centralized/Shared-Memory)
(2) Database Applications
- server-client 구조 상의 두가지 종류라는 것 잊지 말자.
ⓐ Two-tier architecture

- application이 client 단에 위치하여 user와 database system의 네트워크를 담당한다.
ⓑ Three-tier architecture

- application 단이 분리되어서 client 단에 application client가 위치하고, server 단에 application server가 위치한다.
- application client에서는 data의 전처리 작업을 하고, application server에서는 data에 접근하는 작업을 한다.
- application server는 database system와 query를 주고 받으면서 통신한다.
- 현재 대부분읜 database가 갖는 구조이다. 성능과 보안이 Two-tier database보다 좋기 때문이다.
5. Database Users and Administrators

(1) Database Users
ⓐ Naive users (일반, 비전문가)
- user interface를 통해 system과 상호작용하는 user이다.
- web이나 mobile application user 등이 예시이다.
ⓑ Application programmers (개발자)
- application program을 개발하는 개발자이다.
ⓒ Sophisticated users
- program을 작성하지 않고 database에 query문을 날리거나, 분석 sw 등의 도구들을 이용하여 database system와 상호작용하는 user이다.
- Data 분석가 등이 예시이다.
ⓓ Database administrator
- DB 관리자이다.
(2) Database Administrator
- DBA (Database administrator) : DB에 중앙 제어 권한을 가지고 있는 사람이다.
- DBA 역할
① schema definition (최초의 스케마 생성)
② storage structure와 access-method를 생성한다.
③ schema와 physical-organization을 수정한다.
④ data 접근에 대해 승인 / 반려한다.
⑤ Routine maintenance
- 주기적으로 DB를 백업한다.
- 사용 가능한 disk 공간을 확보한다.
- 실행되고 있는 DB 작업을 모니터링한다.
6. History of Database Systems
(1) 1950년대와 1960년대 초기
- magnetic tape를 사용하여 data를 저장하였다.
- 이 tape는 순차적인 접근만 가능하도록 했다.
- punch card가 data의 입력을 위해 사용되었다.

(2) 1960년대 후기와 1970년대
- data에 직접적으로 접근할 수 있는 Hard disk가 사용되었다.
- 네트워크와 계층적 데이터 모델이 널리 사용되었다.
- Ted Codd가 relational data model을 정의하였고, ACM Turing Award에서 상을 받았다.
- IBM research는 R prototype system을 시작했다.
- UC Berkeley는 Ingres prototype을 시작했다.
- Oracle은 첫 상업적 relational database를 출시했다.
(3) 1980년대
- 연구 목적의 relational prototype은 상업적인 시스템으로 발전했으며, SQL이 산업적 standard가 되었다.
- 병렬 분산 database 처리가 시작되었다. (Wisconsin, IBM, Teradata)
- 객체 지향적 database system이 시작되었다.
(4) 1990년대
- 배경 : www의 등장으로 internet이 보급되고 성장했다. 이에 data의 양이 급증하였으며 이를 처리할 DB가 필요했다. Web DB를 위한 interface 개발이 활성화되었다.
- data-mining application이 성장했다.
- data warehouse안에 multi-terabyte data가 존재하게 되었다.
- Web commerse가 등장했다.
(5) 2000년대
- Big data storage system이 발전했다. (Google BigTable, Yahoo PNuts, Amazon, 'NoSQL (Not only SQL)' systems)
- Big data 분석은 SQL을 넘어서 Map reduce, friends가 사용되었다.
(6) 2010년대
- SQL이 재등장했다.
- Map reduce system에 대해 SQL이 front end 단을 수행했다.
- 병렬 database system이 거대해졌다.
- multi-core main-memory databse가 사용되었다.
'[ CS 전공 ]' 카테고리의 다른 글
| [ DB ] Relational Model (2) : Relational Algebra (0) | 2022.03.26 |
|---|---|
| [ DB ] Relational Model (1) : Structure, Database Schema, Keys, Schema Diagrams, Relational Query Lang. (0) | 2022.03.26 |
| [ DB ] 데이터베이스 Introduction (1) : DB 정의, DBMS, DB System (0) | 2022.03.10 |
| [ 네트워크 ] ARP 통신 (0) | 2022.03.03 |
| [ 네트워크 ] VLSM (0) | 2022.03.02 |



