1. Abstract
이 논문에서 이야기하고자 하는 것은 크게 두가지이다.
Interrelationships of image sentiment and visual saliency,
Relation between emotional properties of an image and visual attention
1) Interrelationships of image sentiment and visual saliency
image가 emotion-eliciting stimuli로서 작동한다.
이때, 이미지의 spatial, semantic context를 학습한 model을 생성하는데 DNN을 사용한다.
이 모델은 human attention을 효과적으로 모방하는 모델이며, 인간의 정서적 반응과 시각적 attention 사이의 관계를 정량화 한다.
2) Relation between emotional properties of an image and visual attention
emotion-eliciting content는 초반에는 인간의 attention을 강하게 끌어내지만, 이후로 극적으로 감소한다.
이를 'emotion prioritization effect (감정 우선순위 효과)'라고 하는데, 감정을 이끌어내는 object 쪽으로 rapid, brief한 attention bias (주의 편향)가 발생한다는 개념이다.
데이터셋으로는 EMOd (EMOtional attention dataset)를 사용하는데, 이미지에 대한 '눈의 고정'이 인간의 정서적 반응과 상관관계가 있음을 보여주는 데이터이다.
총 16명의 subject가 있고 image context label 처리가 되어있는데, 총 4개의 label이 있다.
- object contour (대상의 윤곽)
- object sentiment (대상의 감정)
- object semantic category (대상의 의미적 카테고리)
- perceptual attribute (지각 속성)
2. Introduction
선행 연구 사례를 보면 첫번째로, 사람들은 intensity나 color와 같은 이미지의 특성에 따라서 선택적으로 집중한다는 연구 결과가 있다. 한 이미지를 보았을 때 강조되는 특성에 시선이 집중되는 것은 어찌보면 당연한 일이기 때문이다.
두번째 선행 연구 사례로는 사람들이 감정을 유발하는 자극에 더 집중한다는 연구 결과이다. 하지만, 이에 대한 연구가 활발하게는 이루어지지 못했다. 일단, neuroimaging and behavioral studies는 '감정 자극'이 사람의 집중에 미치는 영향에 대한 연구를 진행했다. 그리고 vision 연구에서는 거의 이 '감정을 유발하는 이미지 자극'에 대한 '사람들의 시선 집중'에 대해서 연구된 바가 없는데, emotional stimuli를 포함하는 eye-tracking dataset의 부족으로 인한 결과이다.
따라서, 이 논문에서는 EMOd 데이터셋을 사용하여 이미지의 emotional contents를 포함하는 이미지에 대한 사람들의 시각적인 주의 집중을 확인해본다.
3. Related work
'감정을 유발하는 이미지 자극'에 대한 '사람들의 시선 집중'에 대한 Related work를 소개하면 다음과 같다.
1) Predicting human attention
사람들의 attention을 예측하는 모델에 대한 연구는 상당히 많이 이뤄진 상태이다.
하지만 이미지 전체에 대한 학습이 이뤄지면서 이미지 내의 '여러 객체'에 대해 인간의 attention 우선순위에 대해서는 많은 연구가 이뤄진 것은 아니다.
2) Attention and Emotion
심리학 연구에서 나온 결과로, emotional content에 대한 사람의 집중이 non-emotional content에 대한 것보다 더 크다고 한다. 예를 들면 smiling face나 babies, erotic scenes에 대한 것에 먼저 집중이 된다는 것이다.
Saliency 연구에서는 이미지의 감각적인 특징을 통합하고자 한다. 얼굴, 대상, text를 통합시켜서 saliency를 연구한다. 하지만, 감정과 attention에 대한 수치적인 연구나 모델 개발은 아직 이뤄지지 않고 있는데, 이는 위에서 말한 바와 같이 eye-tracking data와 emotional content를 모두 담고 있는 dataset이 없었기 때문이다.
3) Eye-tracking dataset
대표적인 eye-tracking 데이터셋으로 NUSEF, CAT2000이 있다.
첫번째로 NUSEF (National University of Singapore Eye Fixation)는 emotion-eliciting image들로 구성되어 있다.


두번째로는 CAT2000이다. 2000장의 affective image와 cartoon 등 다양한 이미지로 구성되어 있다.
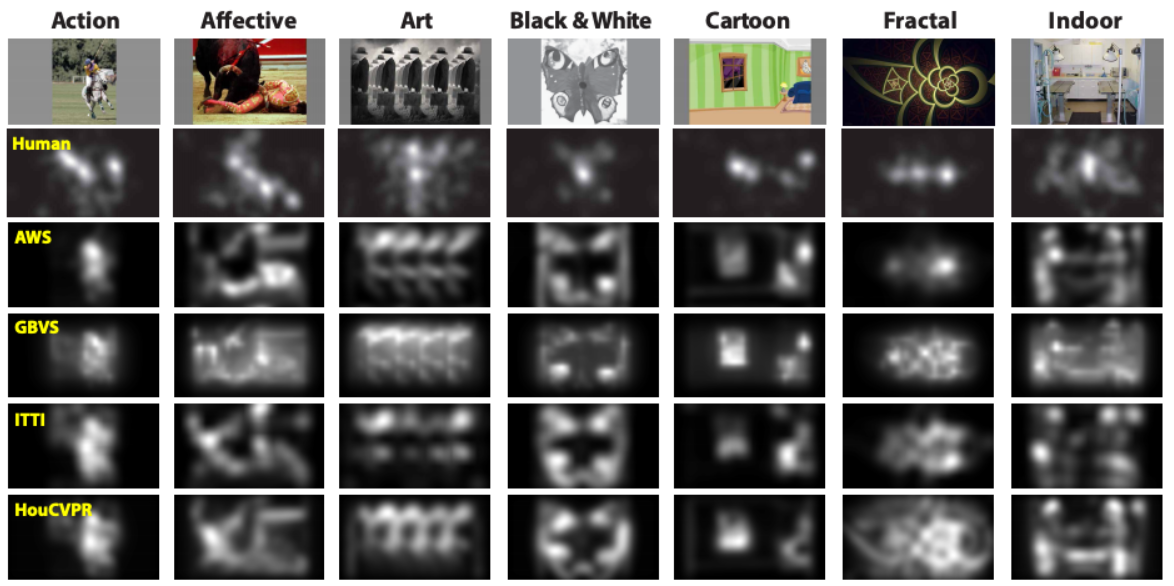
4. EMOd Dataset
논문에서 사용될 데이터셋인 EMOd에 대해서 소개해보겠다.
총 1019장의 emotion-eliciting images with eye-tracking data와 annotations at object, image level 정보를 담고 있다.
label로는 object contour, object name, sentiment category (negative, positive, neutral), semantic category이다. semantic category는 사람들에게 직접적으로 연관된 타입, 시각 제외한 감각과 관련된 타입, 주의를 끌만한 타입, 움직임을 나타내는 타입으로 나누어져 있다.

총 4302개의 segmented object들이 있고, 이 중에 positive는 839개, neutral은 2429개, negative는 1034개이다.

위의 표는 사람들이 attention하는 객체에 대해서 color map으로 표시한 것이다. 사진 옆의 단어들은 해당 attention에 대한 emotion이다.
5. How do sentiments affect human attention?
sentiment가 human attention에 미치는 영향을 알아보기 위해서 'fixation map'을 도입했다. 이는 attention score로 0 ~ 1 사이의 값을 가진다. 사람이 어떤 시각 자극에 주의를 집중하고, 어느 지점에 시선을 고정하는지를 보여주는 지도 형태의 그래픽이다.

(a) : original image
(b) : fixation point로 나타낸 fixation map
(c) : heat map
(d) : saliency map
결과는 총 두가지로 정리해볼 수 있다.
1) Emotion prioritixation effect
사람들은 neutral objects 보다 emotional objects에 더 많은 주의 집중을 한다.
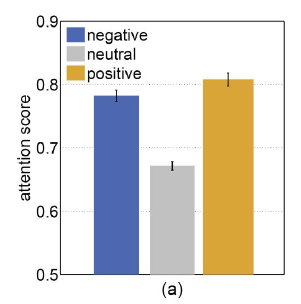
negative, positive objects의 attention score > neutral objects의 attention score

파란색 outline들에 더 많은 attention이 이뤄졌고, 원 안의 숫자는 attention score이다.
우는 아이의 모습이나 깨진 카드에서 감정적인 요소가 더 많이 나왔으며, 사람들은 그곳에 더 많은 집중을 했음을 알 수 있다.
이러한 attention은 강하고 아주 짧게 이뤄지는데, 다음 그래프롤 보면 알 수 있다.
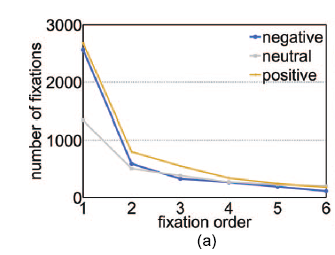
초반에 아주 강한 집중을 했다가 나중에는 집중이 급속도로 사라지는 것을 확인할 수 있다.
2) More attention for human-related objects
사람들은 emotional propeties에 attention을 하면서도 특히, 사람들과 관련이 있는 자극에 attention을 하고 있었다.

인간과 관련된 이미지 (b)와 같이 아이가 우는 장면에서는 attention score가 1.0이다.
인간과 관련되었다고 말하기 어려운, 감정을 판단하기 어려운 장면에서는 attention score가 0.26이다.
6. Model
논문에서 발표한 모델은 'CASNet (Context-Adaptive Saliency Network)'로 VGG16 2개를 병렬적으로 연결하여 학습한다.
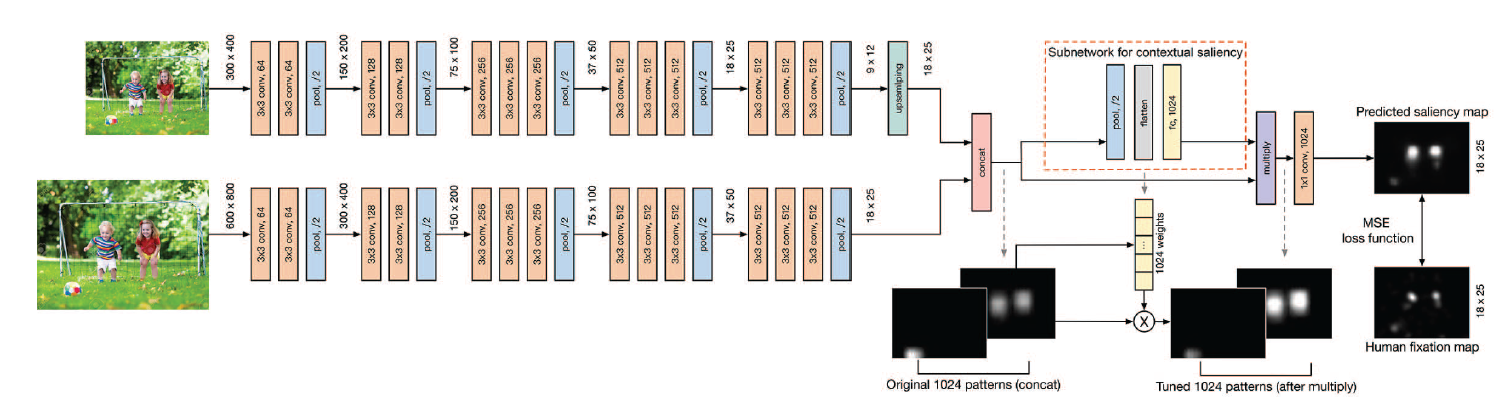
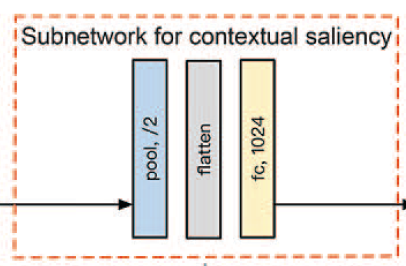
도식의 주황색 박스에서는 emotion prioritization을 위해서 상황 정보를 encoding하는 channel weighting subnetwork를 만들어 두었다. 이를 통해 네트워크가 이미지의 emotion-eliciting objects를 두드러지게 강조하도록 한다.
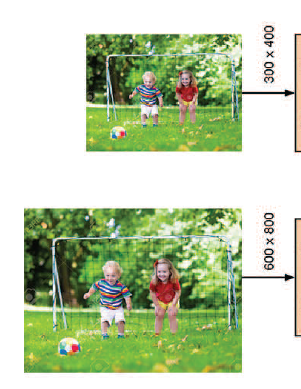
상대적으로 high-resolution deep feature를 추출하기 위해서 800 x 600 x 3 픽셀의 fine-scale 이미지를 첫번째 VGG 스트림에 넣고, 상대적으로 low-resolution deep feature를 추출하기 위해서 400 x 300 x 3 픽셀의 coarser-scale 이미지를 두번째 VGG 스트림에 넣었다.
두 네트워크의 스트림 출력이 동일한 공간 해상도로 re-scale 되고, 함께 stack 되어서 multi-scale deep feature를 형성했다.
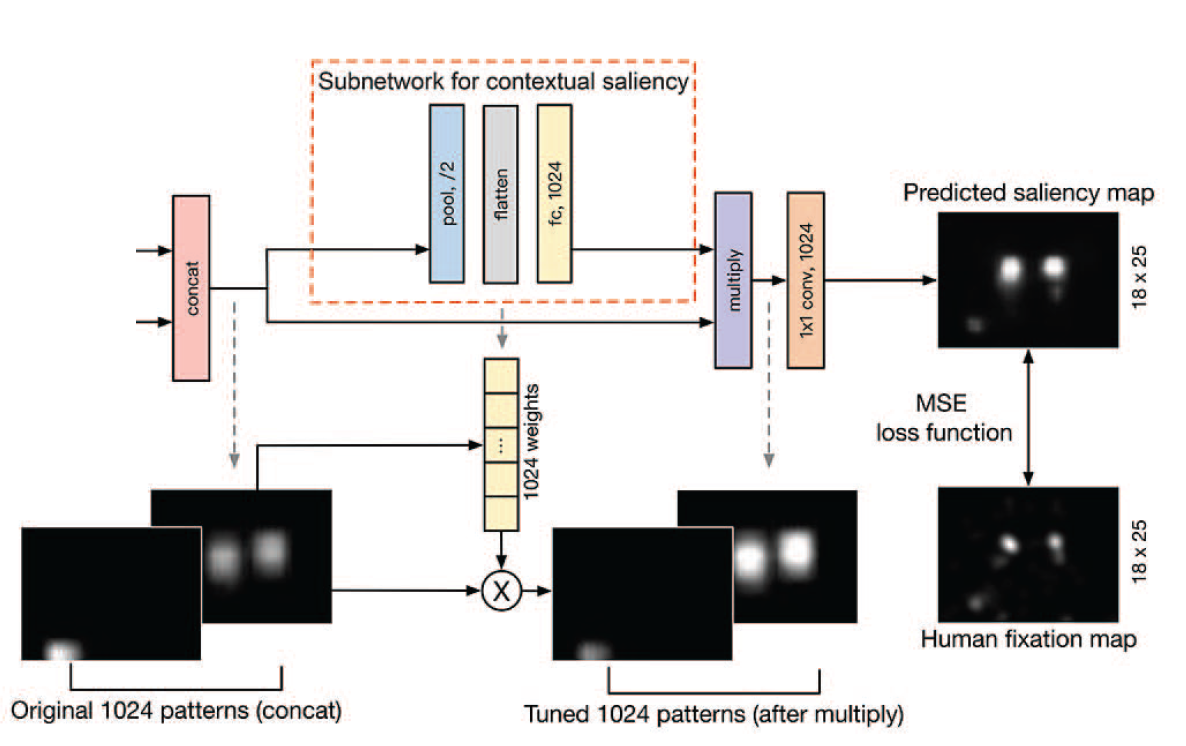
Subnetwork 후에 1 x 1 convolution 연산을 통해서 1024 채널의 이미지를 1 채널 Saliency map으로 만든다. 그 후에 Saliency map을 다시 원래의 크기로 조정하여 loss function을 구하는 작업이 가능하도록 한다.
1 x 1 convolution 연산을 사용해서 채널 수를 줄이는 이유는, Saliency를 위해 모델이 중요한 정보에 집중하고 즉, 이미지에서 attention 부분에 집중하면서 불필요한 정보를 제거하기 위함이라고 추측해볼 수 있겠다.
7. 결과
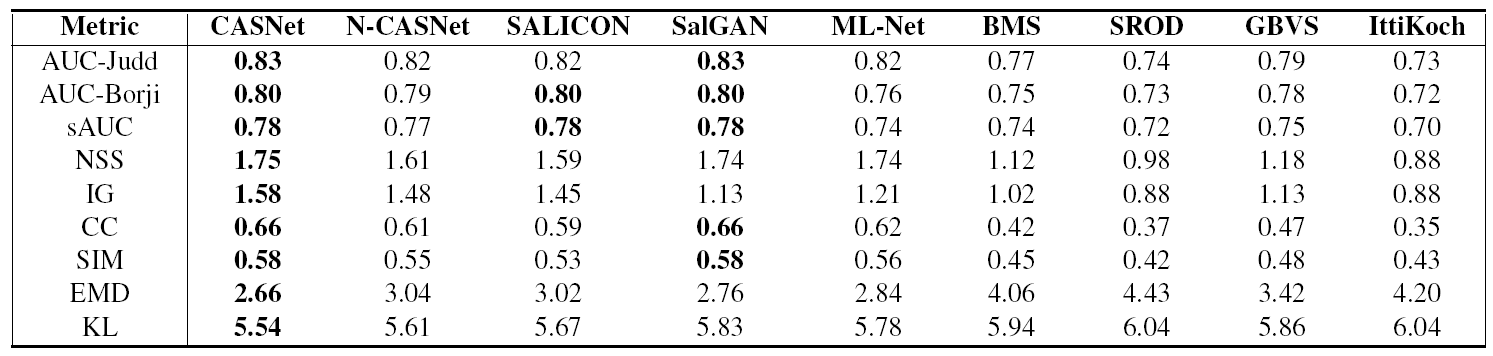
CASNet 모델의 성능이 다른 모델들 중에서 가장 뛰어난 것으로 나왔다.
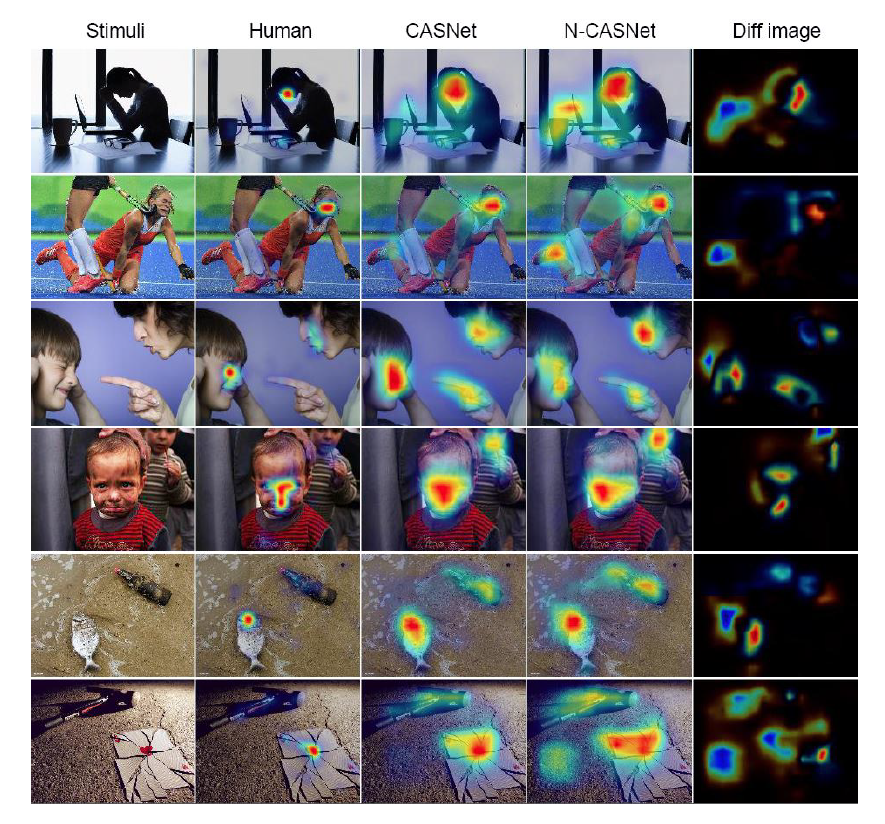
N-CASNet은 CASNet 모델에서 subnetwork가 없는, 즉 contextual saliency 특징을 추출하는 과정이 없는 모델을 말한다. 그러다보니 CASNet에 비해 산만한 attention을 보인다. CASNet은 Human의 결과와 비교했을 때 거의 차이가 없다.
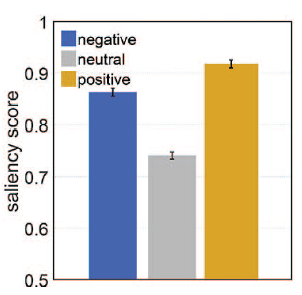
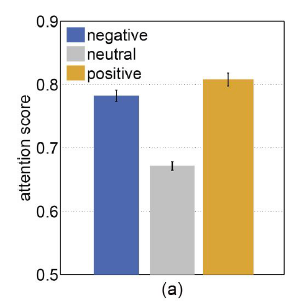
왼쪽은 CASNet의 saliency score이고 오른쪽은 Human의 saliency score인데 별로 차이가 없다는 것을 확인할 수 있다. CASNet 모델이 인간의 감정 우선 순위를 modeling 하는데 상당한 능력이 있음을 보여준다.